
|
96| 1
|
PDF转Word彻底告别收费时代,这个OCR开源项目要逆天! |


 发表于 2022-12-11 19:04:38
发表于 2022-12-11 19:04:38

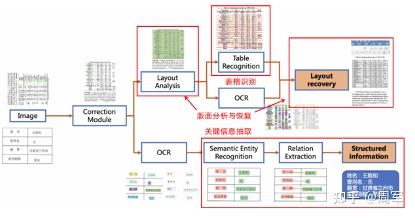
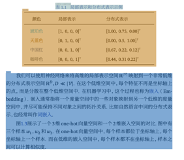

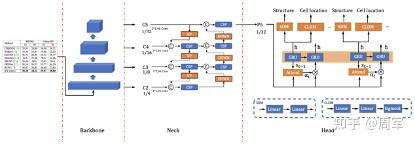



Copyright © 2001-2013 Comsenz Inc.Template by Comsenz Inc.All Rights Reserved.
Powered by Discuz!X3.4
|
96| 1
|
PDF转Word彻底告别收费时代,这个OCR开源项目要逆天! |
Copyright © 2001-2013 Comsenz Inc.Template by Comsenz Inc.All Rights Reserved.
Powered by Discuz!X3.4